
0. 前言#
Human3R 是基于 CUT3R 的一个前馈方法,用于在世界框架中从随意捕获的单目视频中重建在线 4D 人与场景,CUT3R 主要致力于在单目视频中重建在线 4D 场景,而 Human3R 将其中的人类检测出来,作为独立的预测结果,同时也提高了场景的质量,证明了同时预测人与场景可以共同提升效果。
1. CUT3R#
CUT3R 提出了一个能够解决广泛的 3D 任务的统一框架。该方法采用了一个有状态的递归模型,它会随着每个新的观察结果不断更新其状态表示。给定一个图像流(如视频),这种演化状态可以用于以在线方式为每个新输入生成度量尺度的点图(每像素3D点)。这些点图驻留在一个共同的坐标系中,并且可以累积成一个连贯的、密集的场景重建,该场景重建随着新图像的到达而更新,如图:

原论文:《Continuous 3D Perception Model with Persistent State》
1. 总体框架#
具体来说,CUT3R 的输出是一组 RGB 图像,当一张新图像输入到模型中时,它与对当前 3D 场景的理解进行编码的潜在状态表示交互,如图:
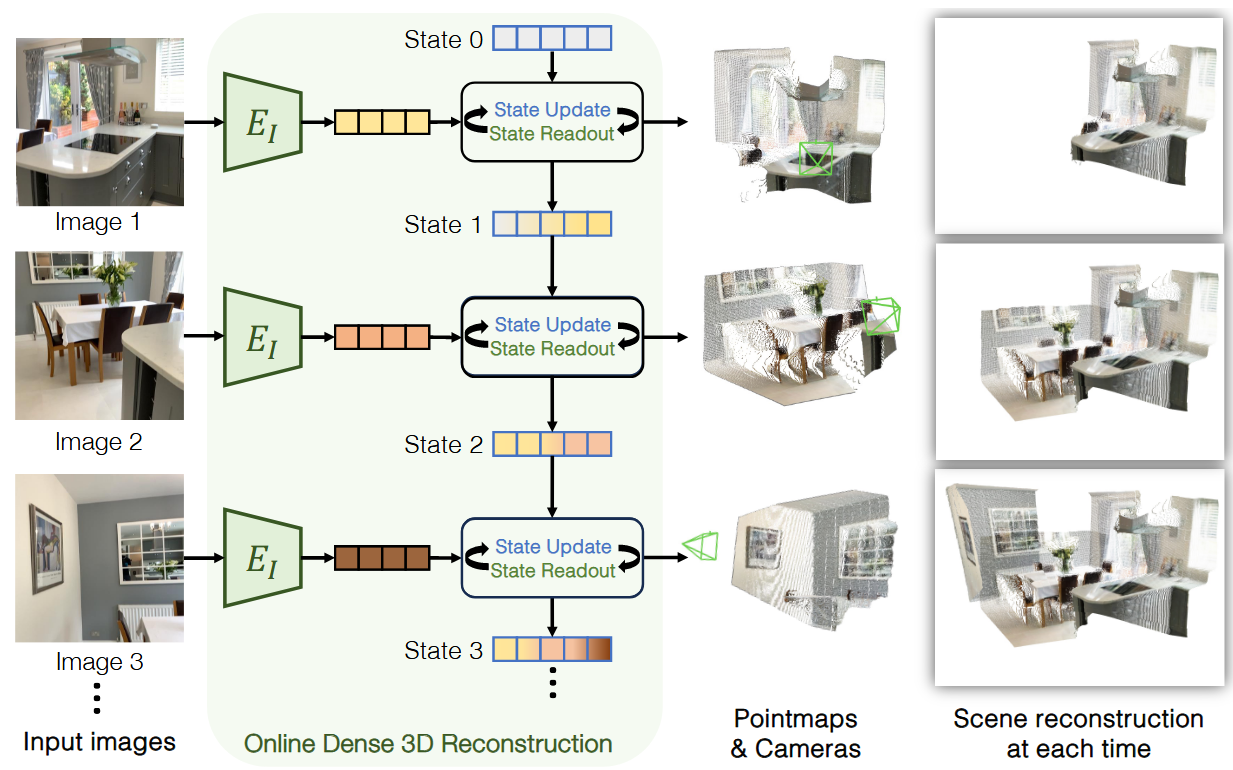
每个输入图像都通过共享权重的 ViT Encoder 编码为视觉 token,与一直存在的状态 token 交互,将当前图像集成到状态 token 中来更新状态(state update),状态读出(state readout)检索状态中存储的过去上下文以进行预测,状态更新和状态读出这两个过程通过两个互联的 ViT Decoder 同时进行。输出包括世界点图(不断积累更新的整体场景)和当前帧点图(当前输入帧构建的场景)以及相对的相机参数。
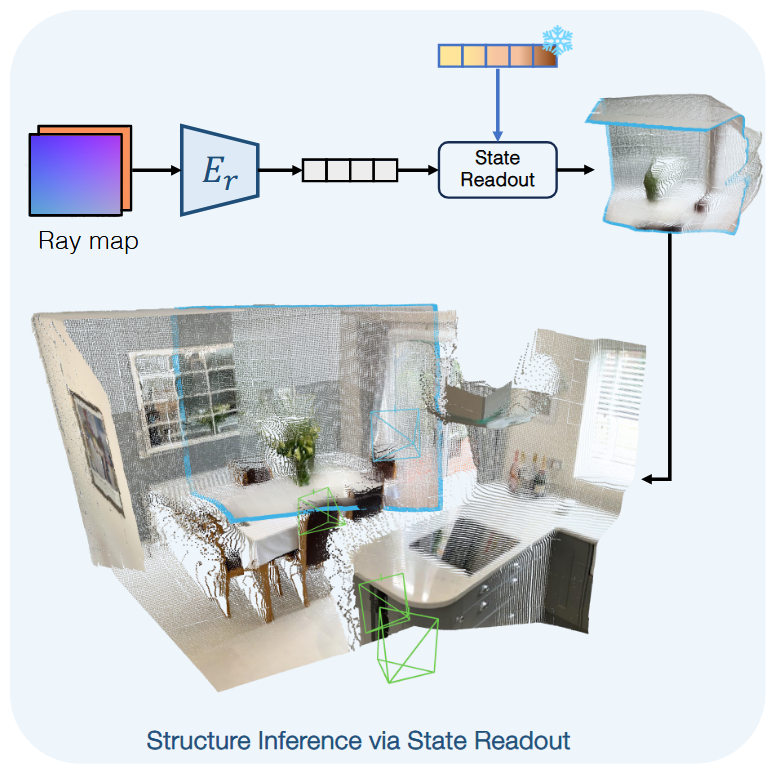
对于不可见的区域,CUT3R 给定一个查询光线图(query raymap),从状态 token 中进行读出操作获取点云,但是这部分只做查询,不做更新,如图,图中蓝色部分即为不可见区域:
2. 训练#
训练时,损失函数包括 3D 回归损失、相机位姿损失、RGB 损失。训练分阶段进行,第一阶段主要在静态数据集的 4 视图序列上训练模型;第二阶段结合了动态场景数据集,提高了模型处理人类等移动物体的能力,以及带有部分注释的数据集,进一步增强了其泛化能力。遵循 DUSt3R,这两个阶段在 224×224 图像上进行训练,以降低计算成本。在第三阶段,以更高分辨率进行训练,使用不同的长宽比并将最大边设置为 512 像素;最后阶段,冻结编码器,仅训练解码器和跨越 4 到 64 个视图的较长序列的头。此阶段的重点是增强场景间推理并有效处理长上下文。
2. Human3R#
在 CUT3R 的基础上,该方法将人类从环境中分割出来,一方面借助 CUT3R 的强大先验预测人类动作行为等;另一方面借助人类数据的约束增强场景表示能力。给定一组 RGB 图像,Human3R 能够以在线、连续的方式重建人体和场景,实时估计每个传入帧的全局多人网格、相机参数和密集场景几何形状,如图:

原论文:《HUMAN3R: EVERYONE EVERYWHERE ALL AT ONCE》
1. 人类表示#
人类是一种常见的表示,因此从场景中将其分割出来是有意义的。常用的人类表示方法是 SMPL(Skinned Multi-Person Linear Model) 和 SMPL-X 模型,如图所示:
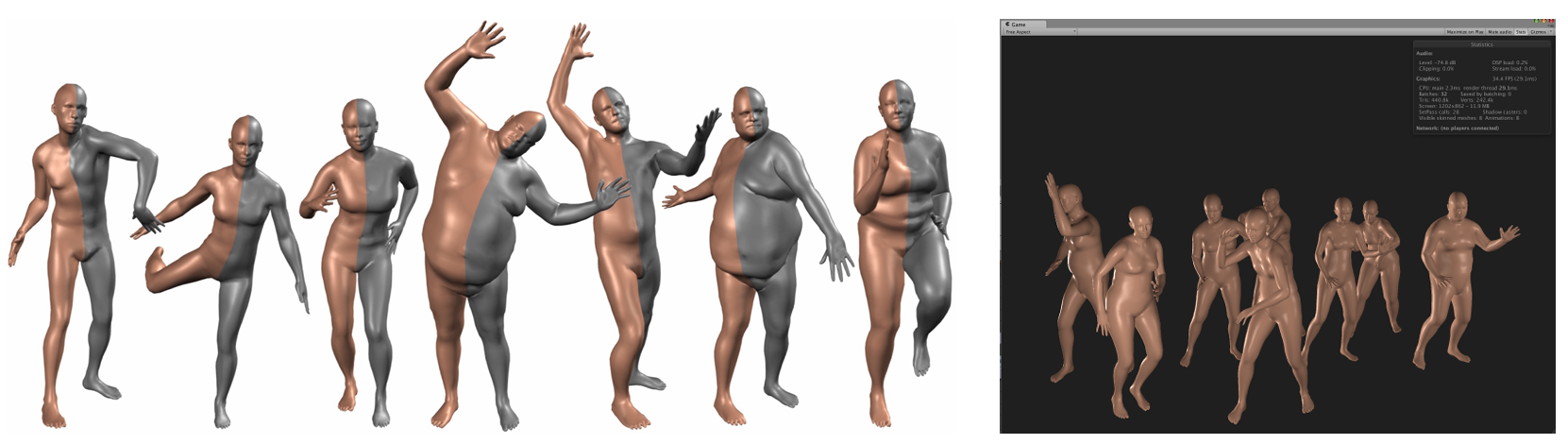
人类有高矮胖瘦,还有不同的动作,将这些分别建模就可以用 SMPL 模型来表示,为了对细节部分(如面部、手足)进行建模,就产生了 SMPL-X 模型。SMPL 模型可以单独表示人类,可以脱离场景单独拿出来使用,如图:
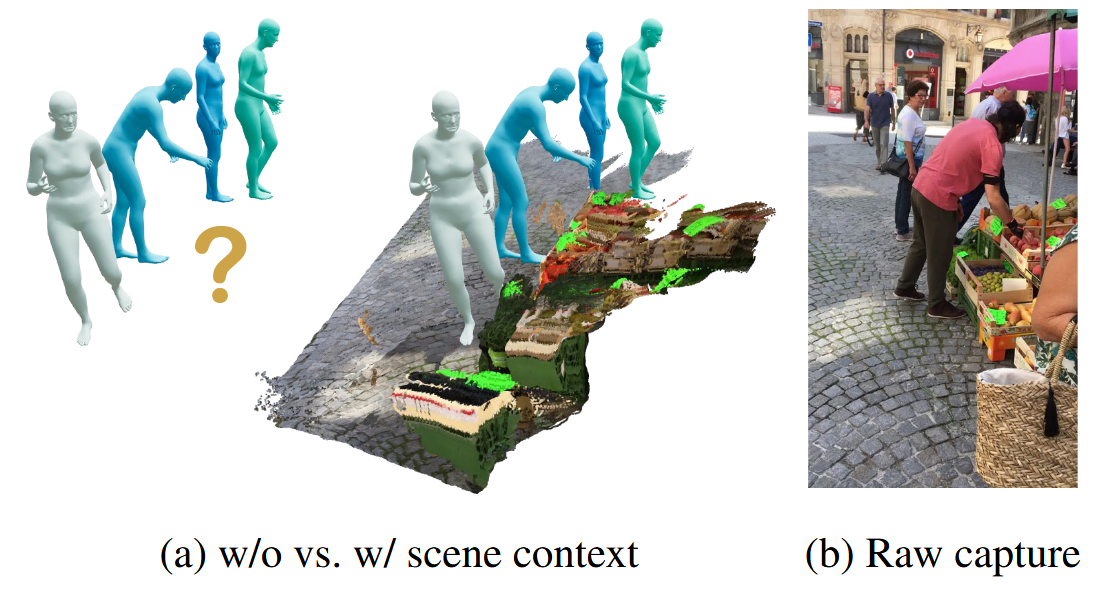
在 Human3R 中认为,使用单独的人类数据训练预测模型是比较困难的,但是在真实环境中就容易去预测或分析人类的动作含义,于是 Human3R 将二者共同训练。
2. all-at-once#
Human3R 是一个一次性(all-at-once)的方法,它只有一个模型、一个阶段、一次前馈、单 GPU 训练一天即可。
- 一个模型:一个统一的模型联合推理人类、场景和相机位姿,而不是依赖每个组件的单独的现成模型。
- 一个阶段:与之前的迭代细化工作相比,该方法以在线方式运行,以实时速度(15 FPS)对流视频进行操作,而不会影响准确性。
- 一次前馈:一次通过自下而上的 SMPL-X 回归器,模型可以在一次前向传递中重建多人。
- 单 GPU 单日:我们的模型参数效率高,只需要在单个 NVIDIA 48GB GPU 上进行一天的训练,即可产生最先进的性能。
3. 总体框架#
框架总体上可以分为两个部分来看,其中一个部分是 CUT3R 对环境、相机位姿等的预测,另一个部分是对人类的预测,如图:
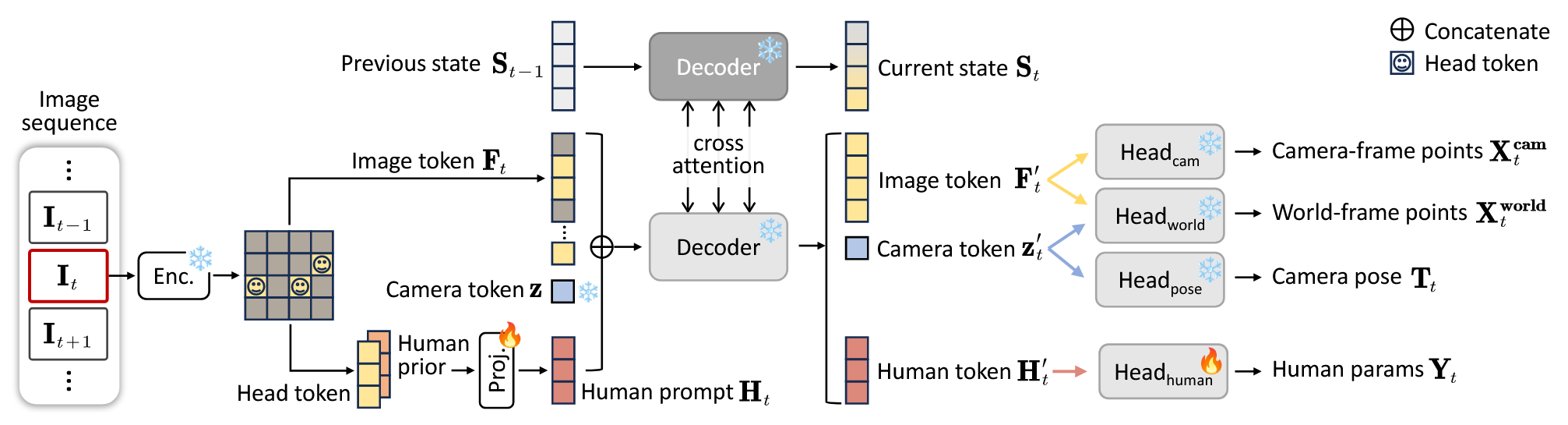
输入一组图像,经过 Encoder 后分为两条路,上面是 CUT3R 的结构,最终能够得到当前帧点云、世界点云以及相机位姿;下面则是人类部分。
对于人类部分,首先检测图像中的人的头部,根据头部来来确定整个人的位置,再通过预训练的人类模型(例如 Multi-HMR)中的人类先验,对整个人构建模型,同时需要在环境中将其对齐。
环境点云与人类模型是同时训练的,环境部分利用了 CUT3R 的先验,人类部分利用了 Multi-HMR 的先验,但通过二者的对齐以及互相促进,使得二者都有提升,并且一次前馈就能预测所有信息。
4. 人类分割与跟踪#
由于人类模型是单独预测的,可以对其进一步操作,使得在场景中识别某个人或跟踪某个人,分析它的一系列动作。这也可以使得在线环境中每个人都有它的标识,而不是只是展示各个时间的所有人,如图:

3. Human3R 的复现#
Human3R 的源代码在这里:fanegg/Human3R
1. 环境搭建#
Readme 中给出的环境配置如下:
git clone https://github.com/fanegg/Human3R.git
cd Human3R
conda create -n human3r python=3.11 cmake
conda activate human3r
conda install pytorch torchvision pytorch-cuda=12.4 -c pytorch -c nvidia # use the correct version of cuda for your system
pip install -r requirements.txt
# issues with pytorch dataloader, see https://github.com/pytorch/pytorch/issues/99625
conda install 'llvm-openmp<16'
# for training logging
conda install -y gcc_linux-64 gxx_linux-64
pip install git+https://github.com/nerfstudio-project/gsplat.git
# for evaluation
pip install evo
pip install open3d
cd src/croco/models/curope/
python setup.py build_ext --inplace
cd ../../../../
我在 ubuntu 20.02 + RTX4090 + 550版本驱动 + cuda 12.2 以及 ubuntu 22.02 + RTX4070s + 550版本驱动 + cuda 12.4 测试,都是可以运行的。
在执行 12 行 pip install git+https://github.com/nerfstudio-project/gsplat.git 时有可能报错,大概意思是无法 import torch ,这种情况可能是第 6 行的 pytorch 与 cuda 版本不符,也可能是 requirements.txt 中重复安装导致各种意外问题,可以尝试运行第 6 行后直接运行第 12 行,之后再运行其他行,就可以 import torch 了。
若在 18 行报错,尝试重新安装 cuda 或检查 ~/.bashrc 中 cuda 的环境变量。
2. 数据和模型下载#
# SMPLX family models
bash scripts/fetch_smplx.sh
# Human3R checkpoints
huggingface-cli download faneggg/human3r human3r.pth --local-dir ./src
第 2 行的命令分为两个部分,首先要在 https://smpl-x.is.tue.mpg.de 和 https://smpl.is.tue.mpg.de 两个网站注册登录,然后将账号密码分别输入,才能下载;最后需要在 google 云盘中下载。三部分文件都可以在浏览器单独下载。
第 5 行的网络参数是在 huggingface 中,也可以单独下载。
3. Inference Demo#
输入可以是一个视频,也可以是一组图像放在一个文件夹中,前面下载的 human3r.pth 可以放在src 文件夹下,--seq_path 后面是 input 的路径。通过查看 demo.py 文件可以知道,--save_smpl 和 --save_video 参数可以保存结果,且必须同时启用才能保存视频。
# input can be a folder or a video
# the following script will run inference with Human3R and visualize the output with viser on port 8080
CUDA_VISIBLE_DEVICES=0 python demo.py --model_path MODEL_PATH --size 512 \
--seq_path SEQ_PATH --output_dir OUT_DIR --subsample 1 --use_ttt3r \
--vis_threshold 2 --downsample_factor 1 --reset_interval 100
# Example:
CUDA_VISIBLE_DEVICES=0 python demo.py --model_path src/human3r.pth --size 512 --seq_path examples/GoodMornin1.mp4 --subsample 1 --use_ttt3r --vis_threshold 2 --downsample_factor 1 --reset_interval 100 --output_dir tmp
# Example 2:
CUDA_VISIBLE_DEVICES=0 python demo.py --model_path src/human3r.pth --size 512 --seq_path examples/images --subsample 1 --use_ttt3r --vis_threshold 2 --downsample_factor 1 --reset_interval 100 --output_dir tmp --save_smpl --save_video
这个 Demo 运行的条件很简单,只要环境配置没问题,有一个视频或图像文件夹作为输入,就能运行和保存结果。如果 Demo 运行不了,大概率是环境配置有问题,若是 Demo 运行中断或迟迟不能得到结果,多半是输入太大,可以调整视频长度或图像数量。
下面对 Demo 进行简单分析,以官网的 demo.py 为准。
程序从 main() 函数开始执行,调用 parse_args() 解析命令行参数,如果有输入则调用 run_inference(args)。在 run_inference() 中首先进行环境初始化,检查计算设备(cuda 或 cpu),通过 add_path_to_dust3r() 将模型路径插入到系统路径,确保 python 能够优先导入该文件。
首先要调用 parse_seq_path(p) 准备数据,p 是 args.seq_path,如果 p 是目录,则直接将其内部的图像路径放入 img_paths,否则 p 是视频,使用 cv2 库的函数将其分割成一组图像,放入临时文件夹 tmpdirname 中。
Human3R 的核心模型是 ARCroco3DStereo,将参数读入后,即调用 prepare_input 进行输入准备,设为 views 。在 prepare_input 中,img_res 如果存在,则会为每个视图添加 img_mhmr 和 K_mhmr 字段,img_mhmr 是经过 padding 处理后的图像,尺寸为 img_res ,K_mhmr 是对应的相机内参矩阵,相当于 img_res 是设定的图像分辨率。 prepare_input 函数接下来将每张图像都参数化,根据有无 raymaps 分别设置。