
0. 前言#
单目场景重建是一个具有挑战性的任务,通过一张图像对三维场景进行重建,并进行新视图合成。Flash3D 是一种仅从单个图像进行场景前馈 3D 重建的方法。
原论文在此:《Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image》
之前的单目场景重建方法大多都在封闭世界中运行,即对某个场景相关的数据集进行训练,泛化性不好。并且,由于体渲染和隐式表示,常常速度较慢、计算成本较高。
对于单个物体的三维重建,最近的 Splatter Image 方法基于 3DGS 实现了快速的三维重建。对于未观察到的表面,该方法利用了一些背景像素来建模物体的遮挡部分,然而对于场景重建并没有这种背景像素可以参考。
为了解决泛化性和速度的问题,本文提出了两种思想:
- 为了解决泛化问题,通常需要扩大模型规模,提升数据量,构造大模型;于是本文基于预训练的深度预测大模型进行改进,实现场景重建任务。
- 为了提升速度、降低计算成本,考虑使用 3DGS 来场景重建,由于只有单目,对于遮挡部分的构建就极为重要;本文对每个像素都预测多层高斯分布,每条射线的第一个高斯分布符合深度估计,模拟场景的可见部分,其余的高斯分布则模拟遮挡或截断部分。
1. 网络架构#

这里的高斯参数与 3DGS 中的高斯参数是一样的,而每个像素的射线上取多层高斯又类似 NeRF 的体素密度。既利用了 NeRF 的思想将三维重建与二维图像联系起来,又借助 3D 高斯提升建模的速度和精度。
2. 核心思想#
1. 分层高斯#
为了新视角合成有更好的效果,本文考虑在不可见或遮挡部分也进行预测,由于 3DGS 的精度和速度,本文也采用 3D 高斯进行重建。参考 NeRF 的体素密度思想和 pixelSplat 的分层高斯思想,本文将每个像素对应一条射线,每个射线上分布多层高斯,将高斯叠加投影可以还原该像素。
由于需要训练多层高斯,高斯的深度就需要较为精准,于是考虑利用一个预训练的深度预测大模型,用于预测准确的深度图,从而给出初始高斯分布(深度图的深度值为每条射线第一个高斯的位置)。
不仅如此,由于单目深度预测模型能力强大,对于几何特征有很好的预测能力,因此借助预训练的深度预测大模型可以直接简化训练难度。把从零开始几何重建的困难问题变成已知场景结构对不可见部分进行补全的简单问题。
2. 边界填充#
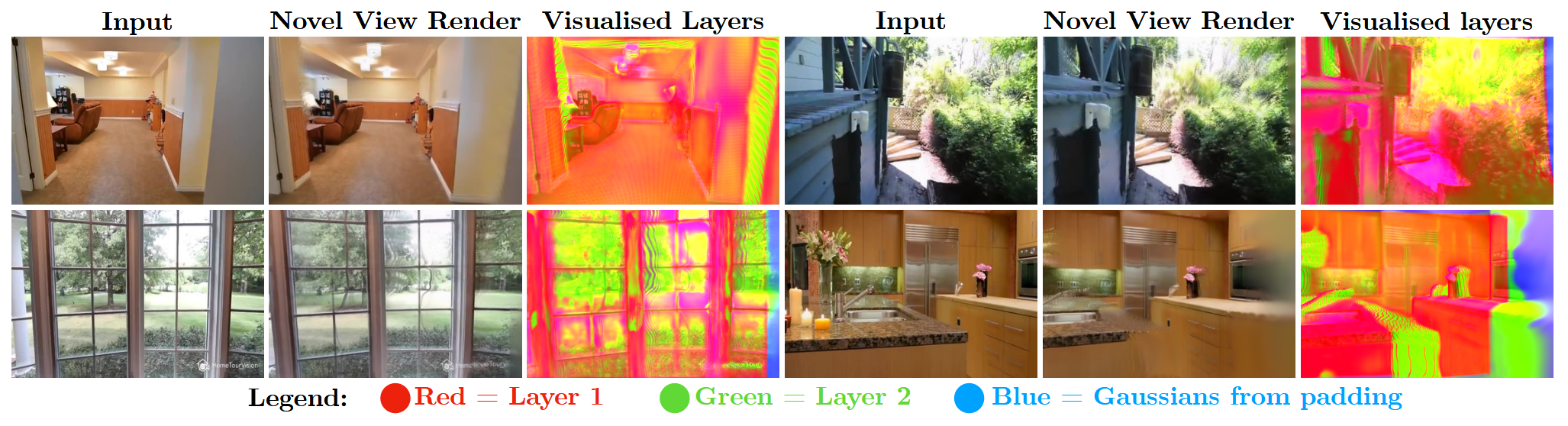
在图像边界附近时,射线向外延伸时很快就会出界,没有足够的上下文像素来提供稳定的深度或外观估计,容易导致边缘区域的不完整或裁断。对于相机拉远的情况,网络需要能够填充原本不在相机中出现的视角,让其保持连续。
于是文中在边界出添加额外的高斯点,这些高斯点不一定严格依赖深度预测,而是通过偏移或颜色补偿来填补,用于在边界平滑过渡到外部区域。如图:
3. 泛化性#
相比 NeRF 的单个模型对应单个场景,本文由于借助了预训练的深度预测大模型,只是利用前馈网络实现了遮挡视角的补全,因此可以用于任意场景,泛化性很好。
消融实验也指出,预训练的深度预测大模型对场景的几何结构等特征有很好的先验,对本文的方法也有举足轻重的影响。
3. 参考文献#
1.牛津VGG团队最新开源!Flash3D:一张图像重建整个3D场景!通用性超强! - 知乎
2.ChatGPT