
0. 前言#
3DGS 是现在比较流行的新视角合成任务的方法,兼顾了质量与速度,然而仍存在许多不足。例如在稀疏视图下,3DGS 具有明显的伪影和模糊,为了增强稀疏视图下的 3DGS 效果,考虑利用其他网络结构或特征来辅助约束,其中一个常用的方法就是 Diffusion。
接下来介绍的几个方法都对此问题进行了改进。
1. DIFIX3D+#
Difix3D+ 是利用单步 Diffusion 模型来增强稀疏视图下 3DGS 的方法,核心思想是利用预训练的 Diffusion 模型的强大先验,对 3DGS 新视角合成的模糊图像进行增强,处理后的新视角图像作为新的约束再送回 3DGS 训练,从而提升 3DGS 质量。
文章链接:《DIFIX3D+: Improving 3D Reconstructions with Single-Step Diffusion Models》
1. 核心架构#
其实在这类方法中,通常都会隐去原始 3DGS 的描述,实则是两个模块。一个是原始 3DGS 训练架构,输入稀疏视图,输出三维重建结果和新视角合成图像;另一个才是文中的增强方法。下面只介绍文中方法,而隐去原始 3DGS 的描述。
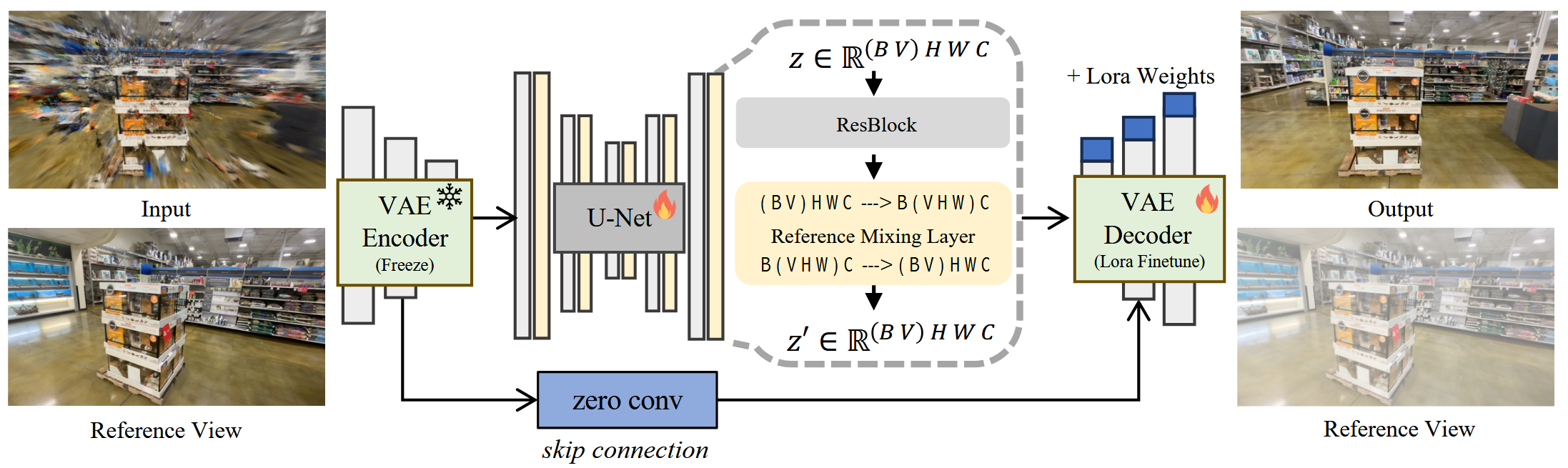
如图,输入为 3DGS 的新视角合成图像,参考图像为稀疏视图的真值图像。通过一个以 U-Net 为基础架构的 Diffusion 模型,将输入图像增强成清晰的图像输出。输出图像反过来作为 3DGS 网络的约束,再一次训练 3DGS 网络。
这里的 Diffusion 模型的 Encoder 是冻结的预训练的参数,目的是利用预训练的先验,实际训练过程中只对 Decoder 进行微调。
可以看到,参考视图和输入视图并不是同一个视角,因此对于这个问题,文中将两个相机视角之间的变换构建了变换矩阵,从而将参考视角针对输入视角进行约束。又因为是 U-Net 网络,所以可逐层约束。
2. 推理增强#
核心架构其实只是 Difix3D,文中的方法其实是 Difix3D+,这个 + 其实是指在推理过程中,得到的图像依然存在伪影。于是再次应用该模型,对新视角合成的结果进行增强,从而能够得到更加精细的合成图像。如图:
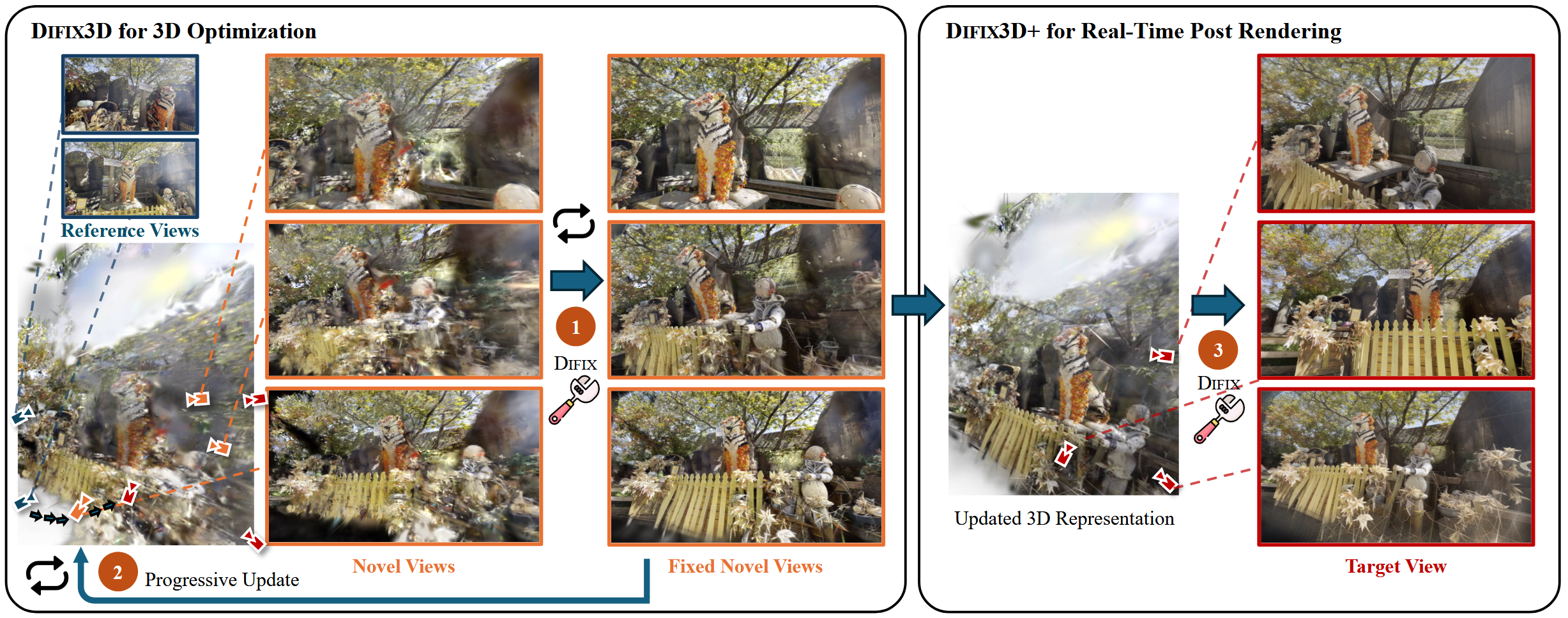
图中左侧是训练过程,右侧则是推理过程。
2. GSFixer#
GSFixer 的思想与 Difix3D 有所相似,对于稀疏视图的 3DGS 训练,也是通过 Diffusion 模型将新视角合成图像进行增强,再输入到 3DGS 中提升训练效果。如图:
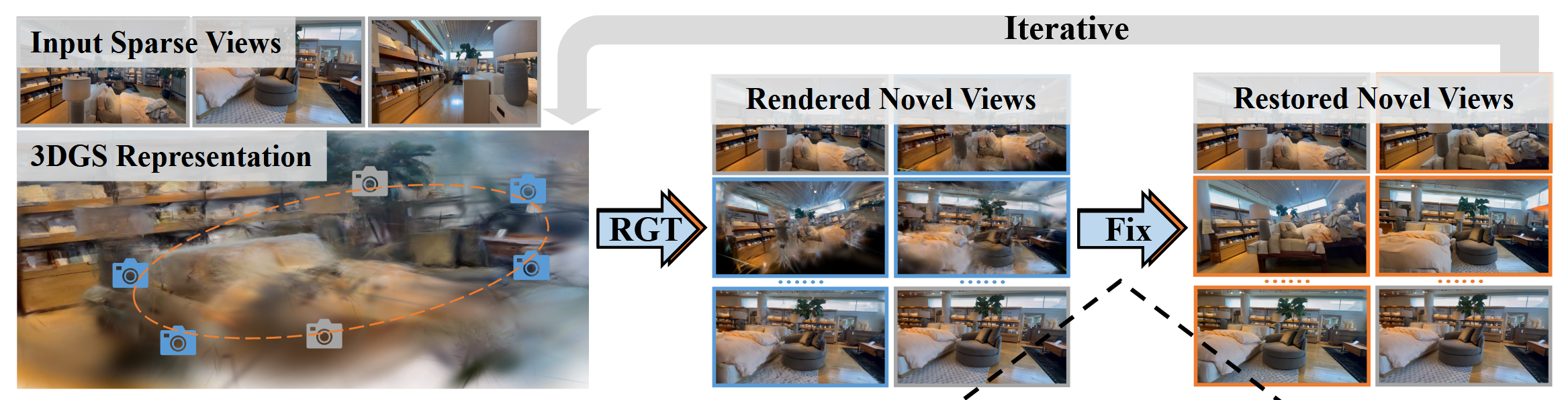
文章链接:《GSFIXER: IMPROVING 3D GAUSSIAN SPLATTING WITH REFERENCE-GUIDED VIDEO DIFFUSION PRIORS》
1. 网络架构#
GSFixer 的核心思想是利用多模态的特征,从稀疏视图中提取出新视角的各类特征,从而增强新视角的图像质量,使得图像更忠实于该场景,而不是完全利用 Diffusion “见多识广”的猜测。
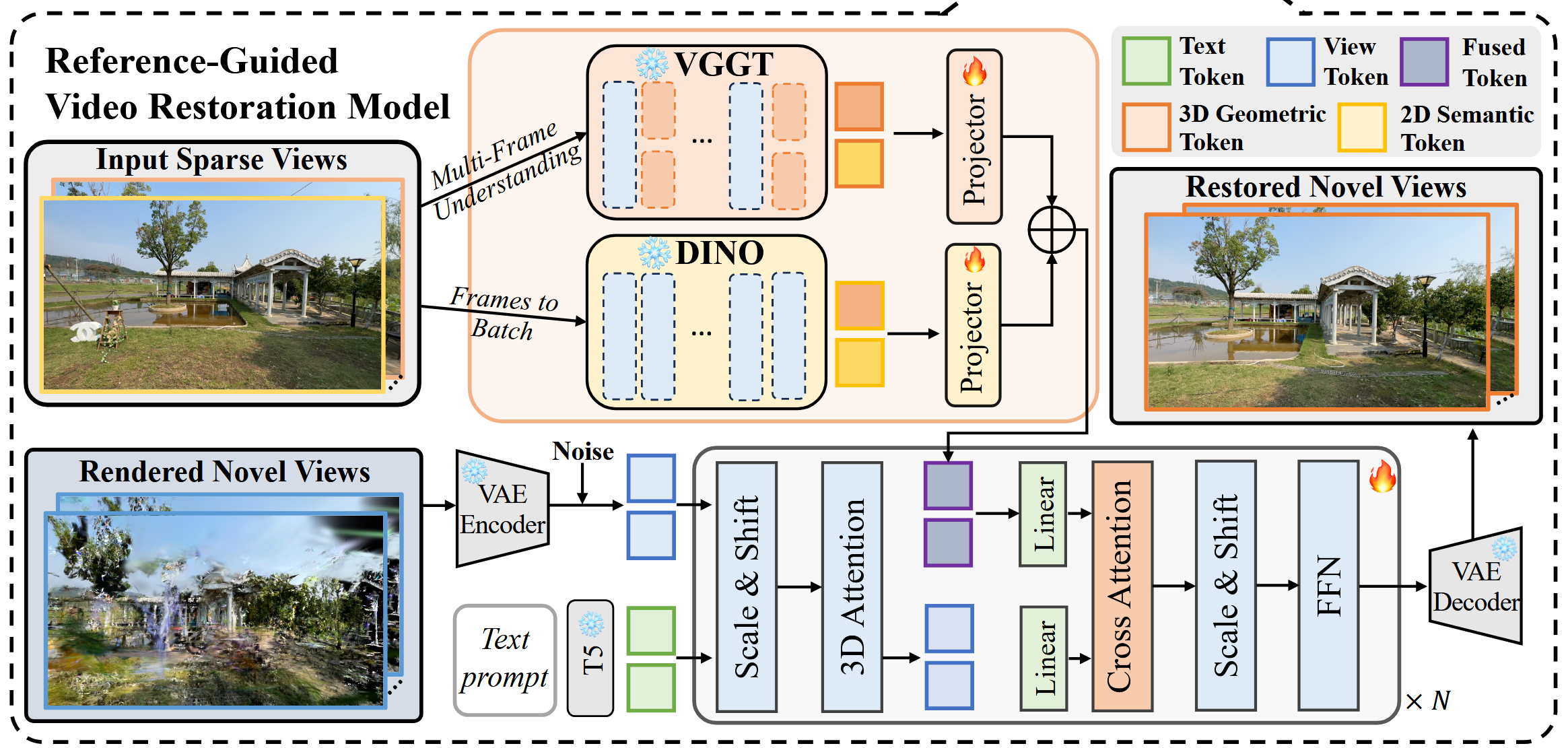
如图,该架构的名字是参考引导的视觉重建模型(Reference-Guided Video Restoration Model)。输入 3DGS 渲染的新视角图像和稀疏视图真值;对于真值,使用 VGGT 提取其 3D 特征,使用 DINO 提取其 2D 特征,将二者统一维度后融合,作为 Fused Token;对于场景的描述文本,提取其语义信息,作为 Text Token;对于新视角合成图像,输入到 Diffusion 模型中,其中 Encoder 依然是冻结的预训练参数,该 Diffusion 模型基于 Transformer 架构进行训练,利用多个模态的特征,最终还原一个清晰的新视角图像。
2. 参考引导轨迹采样#
对于稀疏视图来说,视图之间的空隙很大,在何处采样作为新的约束至关重要,文中提出了一种策略,即参考引导轨迹(Reference-guided Trajectory)的采样策略。如图:
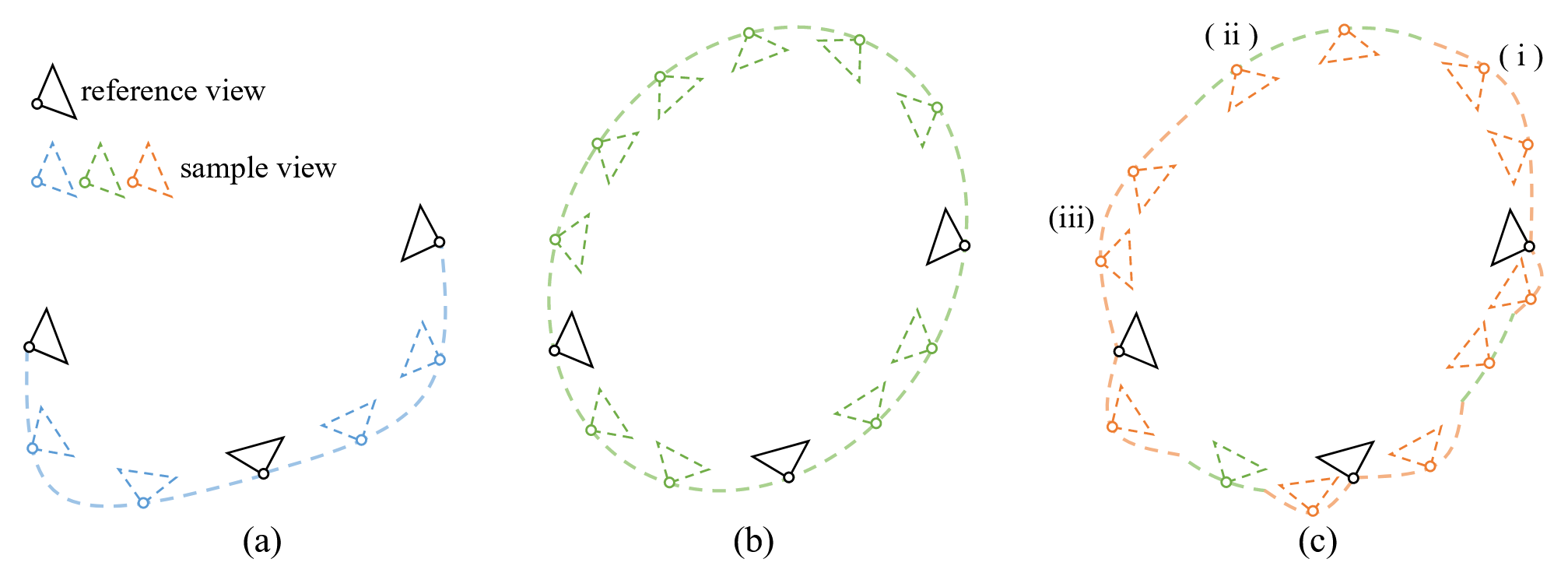
图 (a) 为插值轨迹,图 (b) 为椭圆轨迹,而图 (c) 则为参考引导轨迹。插值轨迹的质量较高,但角度泛化性不足;椭圆轨迹的视角广泛,但质量次优。因此,为了平衡两种轨迹,参考引导轨迹的策略为:首先从参考视图插值到球面路径上最近的视点,沿球体路径对其他视图进行采样,然后插值到下一个最近的参考视图。
3. FixingGS#
FixingGS 依然是对稀疏视角下的 3DGS 做的改进,但该方法与上述两种方法不同,它并未设计独立的网络架构来增强新视角合成图像,而是直接利用预训练的 Diffusion 模型进行蒸馏,并利用无训练的网络直接增强 3DGS 效果。
文章链接:《FIXINGGS: ENHANCING 3D GAUSSIAN SPLATTING VIA TRAINING-FREE SCORE DISTILLATION》
1. 跨视图一致性的蒸馏策略#
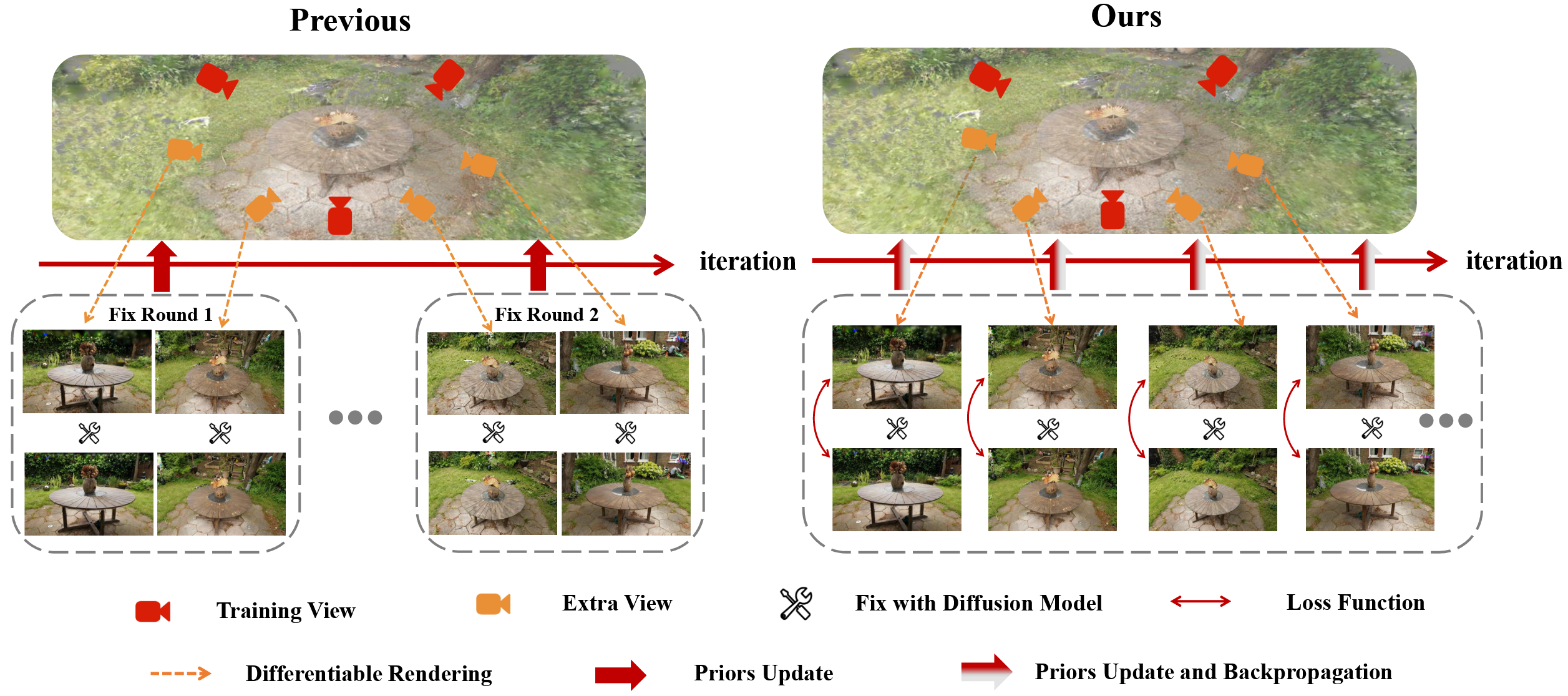
上述两种方法如图左,通过对新视角采样,得到合成视图,增强后再输入回 3DGS,进行一轮一轮的训练。然而,这样的训练方式会导致一个问题:前期得到增强的伪标签约束质量并不高,但会在之后的训练中持续影响训练效果,这使得即使训练多轮,效果提升也十分有限。
于是文章中采用了图右的方法,每次迭代时随机采样一组视角,将这组视角共同送入 Diffusion 的潜空间中,Diffusion 会在潜空间中为这多个视角提供一致的表示,即共享了语义一致性。
该方法的 Diffusion 模型也是预训练的,因此这个过程被称为蒸馏。
2. 无训练#
FixingGS 是一种无训练的方法,即没有训练一个额外的网络来增强 3DGS 效果。在 Diffusion 模型中蒸馏后,会返回一个噪声预测梯度,这个梯度表示输入图像与自然图像的差异。
将这个梯度直接反向传播到 3DGS 中,即可直接修正 3DGS,与前两种方法的不同在于:前两种方法是将 3DGS 的图像输出到新的网络中,通过新网络修复图像,再输入回 3DGS 中;而该方法将这个中转直接去掉,利用预训练 Diffusion 直接蒸馏出 3DGS 所需要的知识,直接进行梯度反传,提升了效率。
4. ProSplat#
ProSplat 是利用单步 Diffusion 模型来增强稀疏视图 3DGS 效果的方法。该方法提出了最大重叠参考视图注入(Maximum Overlap Reference view Injection, MORI)来选择最接近目标视图的参考视图;提出了距离加权外极注意力机制(Distance-Weighted Epipolar Attention, DWEA)来增强目标视图和参考视图之间的交叉视图特征匹配;总体上提升了多视图的一致性,提高了稀疏视图的利用率,从而提升 3DGS 的效果。
1. 总体框架#
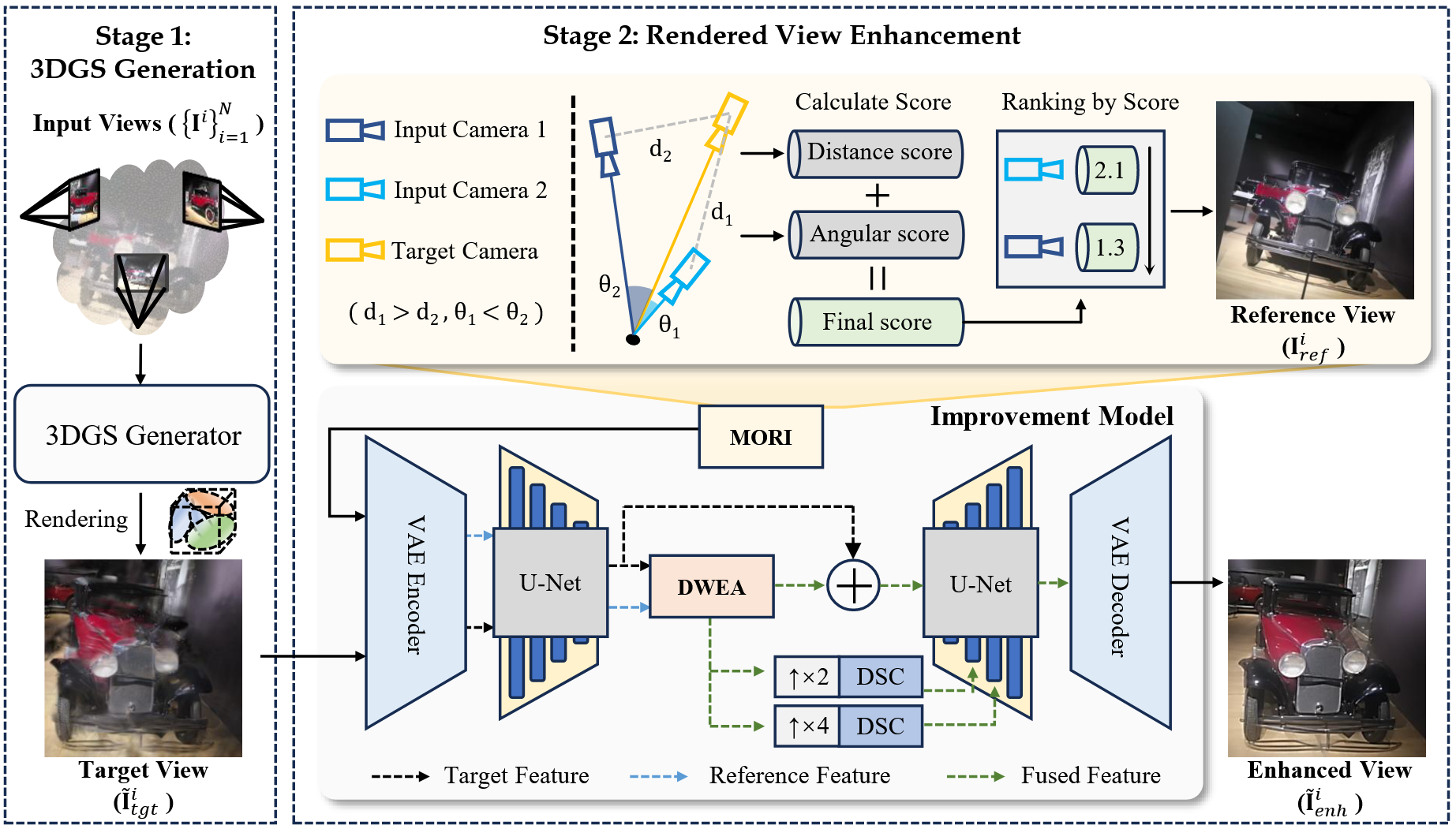
如图,ProSplat 方法分成了三个部分。第一部分是 3DGS 生成部分,稀疏视图约束生成的新视角图像比较模糊;第二个部分是对参考视图进行选择,这里主要用了文中提出的 MORI 方法;将前两部分的结果送入到基于 U-Net 的 Diffusion 网络中进行训练,其中还加入了文中提出的 DWEA 方法进行特征匹配,最终训练一个 Diffusion 网络对新视角合成的图像进行修复。
2. 最大重叠参考视图注入(MORI)#
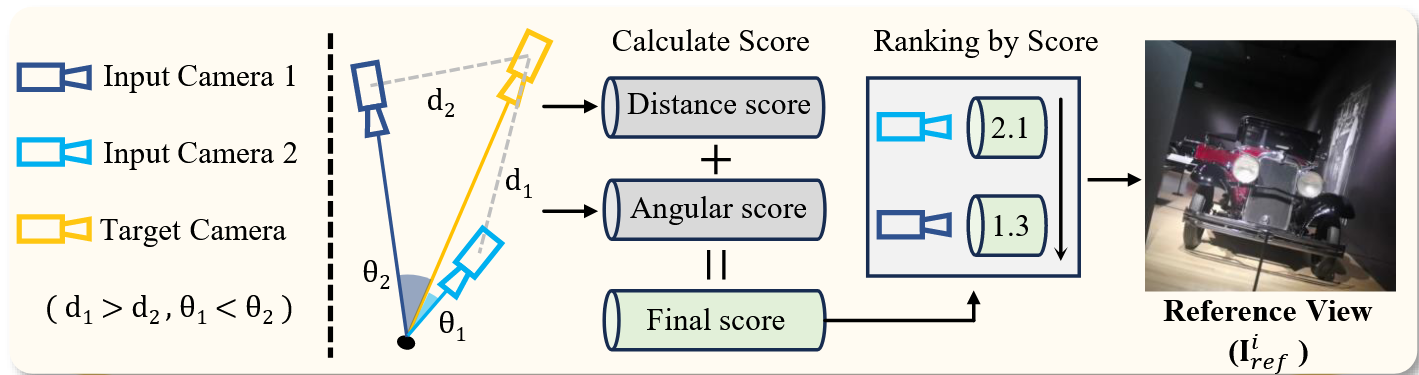
如图,对于黄色的目标视角,稀疏视图的约束有两个,通过计算视图间的偏移量和旋转角度进行近似程度的比较,选择与目标视图最接近的约束作为参考视图。这样可以最大化利用该稀疏约束,也最具有参考价值。
3. 距离加权的极注意力(DWEA)#
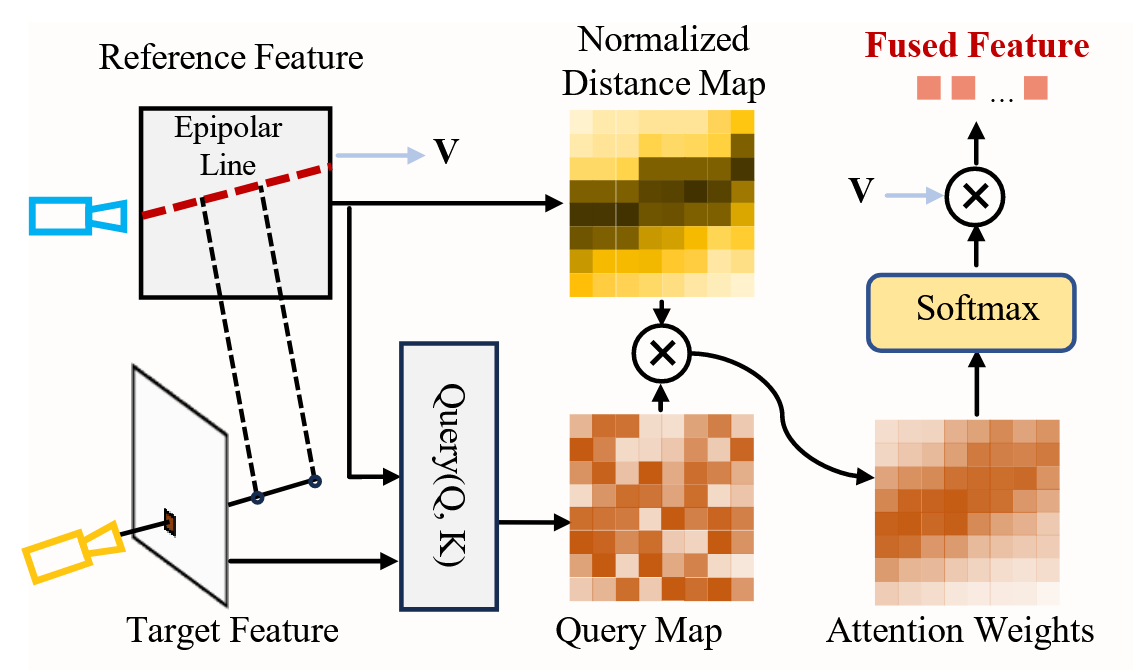
如图,DWEA 本质上是一种注意力机制。对于目标图像和参考图像,一般的注意力机制是将整张图像都进行计算,不考虑其他信息,即全局注意力;又由于有伪影的出现,就容易出现位置错误的地方却有很高的注意力分数。
外极注意力就是根据视图之间的极几何形状调制全局注意力权重。简单来说就是通过目标图像和参考图像来推算其空间几何形状,从而找到其空间几何中对应的区域,再找到其在图像中的对应极线,从而可以得到归一化的距离映射矩阵。将该矩阵调制全局注意力,即可得到距离加权的极注意力。
这种极注意力相比全局注意力更注重影响视图中该像素的极线附近区域,在约束不多或视图质量不高时可以提升注意力准确性。
5. WaveletGaussian#
该方法是利用 Diffusion 对稀疏视图的 3DGS 进行增强的方法,但它选择在小波域应用 Diffusion,即仅在低分辨率 LL 子带应用 Diffusion,而高频子带则使用轻量级网络进行细化。
本文链接:《WAVELETGAUSSIAN: WAVELET-DOMAIN DIFFUSION FOR SPARSE-VIEW 3D GAUSSIAN OBJECT RECONSTRUCTION》
1. 离散小波变换(Discrete Wavelet Transform, DWT)#
这是一种广泛用于计算机视觉的方法,将图像分解过程可描述为:首先对图像的每一行进行 1D-DWT,获得原始图像在水平方向上的低频分量 L 和高频分量 H,然后对变换所得数据的每一列进行 1D-DWT,获得原始图像在水平和垂直方向上的低频分量 LL、水平方向上的低频和垂直方向上的高频 LH、水平方向上的高频和垂直方向上的低频 HL 以及水平和垂直方向上的的高频分量 HH。
在四个分量中,本文仅对 LL 分量进行 Diffusion,其余三个分量采用 U-Net 网络进行细化。
2. 总体框架#
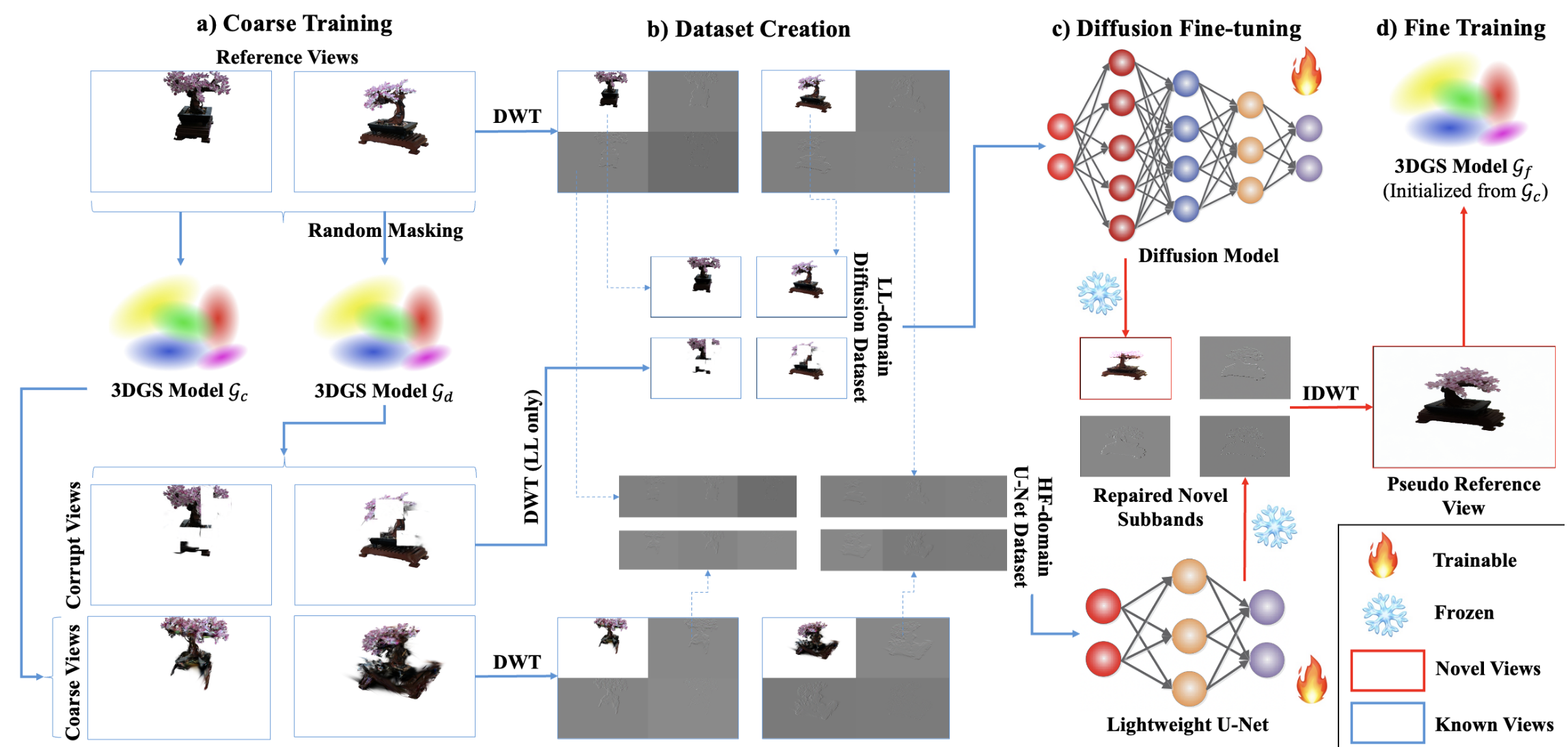
如图所示,输入的稀疏视角为左上角的参考视图,对参考视图直接进行 DWT,得到四个分量作为真值;使用原始的稀疏视图构建一个 3DGS 模型 Gc ,经过 Gc 生成的新视角为粗视图(Coarse Views),将粗视图进行 DWT,获取它的 LH、HL、HH 三个分量,在轻量的 U-Net 中进行细化;再将原始的稀疏视图加一个随机的 Mask 构建一个 3DGS 模型 Gd ,经过 Gd 生成的新视角为有损视图(Corrupt Views),将其进行 DWT 并获取它的 LL 分量,对 Diffusion 进行微调。
当训练完成后,输入新视角的视图,即可得到修复后的新视角的四个分量,再通过离散小波逆变换(IDWT),即可还原新视角的视图,该视图作为伪标签可以进一步增强 3DGS 的效果。
6. 参考文献#
1.ChatGPT