
0. 前言#
DepthSplat 是 CVPR 2025 的一篇论文,将多视角图像与单目深度特征相融合,同时提升深度估计质量和新视角合成效果。一方面,更好的深度估计能显著提升基于高斯点的视图生成质量;另一方面,利用高斯点渲染作为无监督预训练目标,能在大规模无标签数据上训练深度模型,从而提升深度估计精度。
原论文在此:《DepthSplat: Connecting Gaussian Splatting and Depth》
新视角合成与深度预测是两个基础任务。对于新视角合成,3DGS 效果不错,但基于 3DGS 的 SOTA 方法 MVSplat 依赖特征匹配的多视角深度预测;对于深度预测,现有的单目深度预测模型通常在多个视角中缺乏统一尺度。
为了解决这两个问题,本文决定将二者共同解决,因为二者相互影响,深度预测的准确率提升可以提高新视角合成的效果。
1. 网络架构#
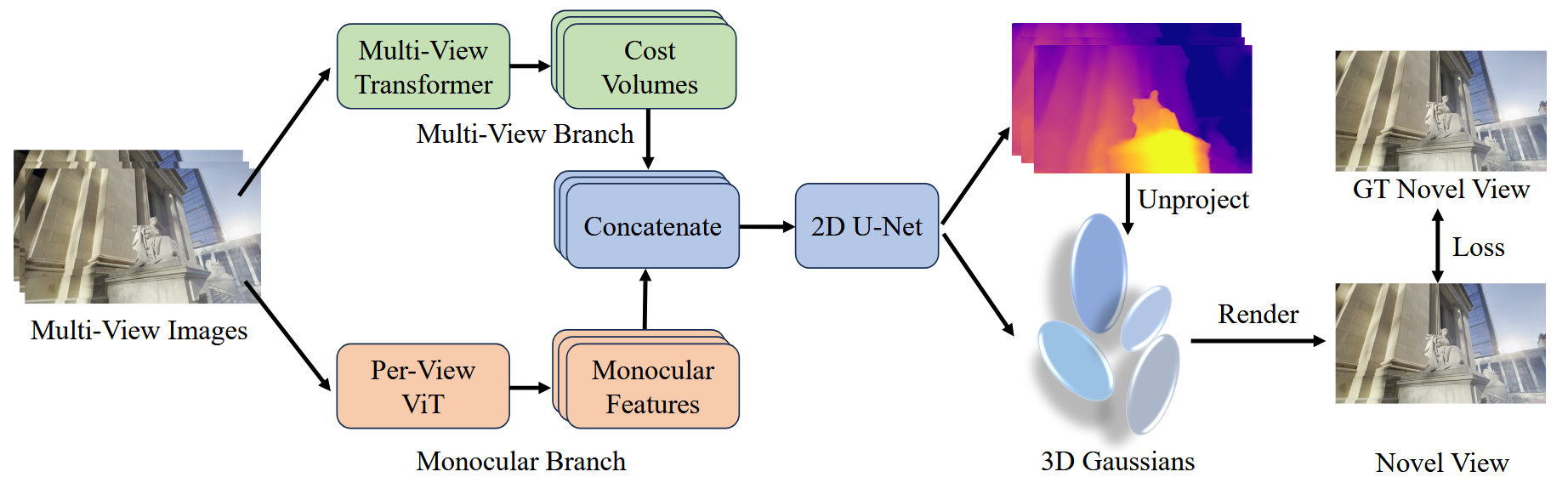
如图,输入为一组多视角的图像和相机位姿,目的是构建每个视角下的深度图。可以看到,多视角的图像分别输入到多视角分支(Multi-View Branch)和单目分支(Monocular Branch),再进行融合。
1. 单目分支#
对于单目分支,直接采用预训练的深度预测大模型提取特征,文中用的是 Depth Anything v2 的骨干 ViT,目的是提取每个视角的单目深度特征。
2. 多视角分支#
多视角分支的目的是提取图像的语义、纹理、结构等特征,并在多个视角间对齐。
具体来说,先用共享权重的轻量 ResNet 对每张图下采样得到局部特征,接着用多视图 Swin Transformer 在各个视角之间做交叉注意力,将相邻视角的特征进行对齐。
在提取多视角特征图后,再用其计算代价体(Cost Volume),代价体的作用就是保证多视角的尺度一致性。以某个参考视角 i 为例,首先在深度范围内采样 D 个候选深度,每个候选深度值设为 dm,将参考视角 i 的相邻视角 j 的特征图按每个候选深度用相机投影矩阵扭正到参考视角 i;对于每个 dm,用点积衡量 j 的扭正特征图与 i 的特征图的相关性,将 D 个深度图的点积结果沿深度维堆叠,得到的张量就是代价体。若特征图的维度为 (h,w),则代价体的维度为 (h,w,D)。
简单来说,对每个像素,沿深度维的一列值就是这条射线上各个深度的匹配得分(越高则说明越可能是正确深度)。构造方式是把其他视角的特征在每个深度假设上扭到该参考视角后,与参考特征做相似度。
之所以要计算代价体,就是因为单目分支没办法预测绝对尺度,因此需要构建多分支间的深度关联,从而使其尺度一致。
3. 特征融合与深度回归#
这里将单目特征与多目特征直接在通道维拼接,实验表明这种简单拼接策略优于注意力融合;用一个 2D U-Net 对拼接后的张量回归到代价体的维度,再对 D 维做 softmax 并对候选深度取期望来得到连续深度,这时会把维度变回特征图维度。最后通过 DPT 头上采样,恢复维度为原图像维度。
这里的目的主要是将多视角分支得到的候选深度用上,并预测出最终深度。
4. 3DGS 渲染#
将得到多视角深度图反投影到三维空间,设为 3D 高斯的初始中心,同时从上一步深度回归后的特征中预测 3D 高斯的其余参数。最后使用 3DGS 的方法,对新视角进行渲染。
5. 总结#
渲染是端到端可微的,即便没有真实的深度标签,只要有多视角图像对,网络就能把预测深度传到高斯,再传到渲染新视角,与真实新视角图像对比,得出渲染损失。渲染损失可以通过这条线路反向传播,从而最终影响到预测深度的准确性。
这样的框架能够在提升新视角合成效果的同时,提升深度预测的准确性,因此这样的框架能够同时提升新视角合成与深度预测的效果。
方法的核心思想可以说是将深度预测与高斯渲染串联,形成一个能够误差反传的回路,训练一个网络能够同时提升两种能力。
然而,该方法的重心依然在新视角合成上,深度预测属于附属任务,虽然在推理时可以单独使用,但训练时仍需借助高斯渲染误差反传。
因此该方法可以这样理解,在提升新视角合成效果时,顺带提升了深度预测效果;或者说,通过提升深度预测效果,而提升了新视角合成效果。不应该理解为,为了提升深度预测效果,通过 3DGS 的渲染来提供海量无监督数据,毕竟论文的名字是 DepthSplat 而不是 SplattingDepth。
2. 参考文献#
1.【CVPR2025】DepthSplat:使用几何一致深度估计增强前馈GS方法-CSDN博客
2.ChatGPT